EKF-SLAM
Estimating the robot pose and landmark map jointly with an EKF.
Definition of the SLAM problem
Given:
- Controls:
- Observations:
Wanted:
- A map of the environment:
- The path of the robot:
We usually aim to solve the online SLAM problem, focusing on estimating the current state of the robot and the landmarks at each timestep.
EKF for online SLAM
We use the (Extended) Kalman filter as a solution to online SLAM, representing the belief as:
The goal is to estimate the robot's pose and the landmark locations simultaneously.
Assumption. Known correspondences (data associations between landmarks and observations are known).
The state space for a robot moving in a 2D plane observing landmarks is:
State representation
With landmarks, the state vector has dimension . The belief is given by a mean and covariance :
The covariance has a key block structure: for the robot pose, for the landmark map, and the cross-covariance blocks that encode the correlations between the robot and the landmarks — which is where most of the magic happens.
Note. In practice we start with only the robot's state and grow the matrix dynamically as new landmarks are discovered.
Filter cycle
The EKF-SLAM algorithm operates in cycles of five steps:
- State prediction
- Observation prediction
- Measurement
- Data association
- Update (correction)
State prediction
In the prediction step, only the robot's pose is directly affected by the controls ; landmark positions remain unchanged. The covariance update therefore touches only the robot-related blocks, with linear complexity in the number of landmarks .
Update step
In the update step, both the robot's pose and landmark positions are updated based on new sensor measurements. Every observed landmark refines not only its own estimate but also — via correlations — the robot's pose and the other landmarks. Unlike the prediction step, this involves updating the entire covariance matrix, giving quadratic complexity in .
Note. Quadratic complexity is intrinsic: observing one landmark refines all other estimates through the cross-covariances .
EKF-SLAM, step by step
1. Initialization
The robot starts in its own reference frame and the landmarks are unknown. The state has dimension :
Note. In practice, landmarks are initialized as they are first observed, updating and expanding the state representation on the fly.
2. Prediction step (motion model)
Using a velocity-based model, the robot's motion in the 2D plane is:
To map this into the full -dimensional state, we use an auxiliary matrix that selects the robot block:
The predicted mean is then with the motion increment applied through .
import numpy as np
# Auxiliary matrix that embeds 3x... into the full state size n
def Fx_embed(n):
Fx = np.zeros((3, n))
Fx[:3, :3] = np.eye(3)
return Fx
# Incremental motion model
def motion_increment(theta, u, dt):
v, w = u
if abs(w) < 1e-9:
return np.array([
v * dt * np.cos(theta),
v * dt * np.sin(theta),
0.0,
])
th2 = theta + w * dt
return np.array([
-(v / w) * np.sin(theta) + (v / w) * np.sin(th2),
(v / w) * np.cos(theta) - (v / w) * np.cos(th2),
w * dt,
])3. Covariance prediction
The covariance update is:
Since the motion model only affects the robot pose, the Jacobian has a block structure:
- is the Jacobian of the robot motion model.
- is the identity — landmarks remain unchanged.
Jacobian of the motion model:
def G_inner(theta, u, dt):
"""Inner 3x3 Jacobian of the motion model (excluding identity)."""
v, w = u
J = np.zeros((3, 3))
if abs(w) < 1e-9:
J[0, 2] = -v * np.sin(theta) * dt
J[1, 2] = v * np.cos(theta) * dt
return J
th2 = theta + w * dt
J[0, 2] = -(v / w) * np.cos(theta) + (v / w) * np.cos(th2)
J[1, 2] = -(v / w) * np.sin(theta) + (v / w) * np.sin(th2)
return JExpanding shows clearly which blocks change:
- is updated by .
- (robot ↔ landmark correlations) are updated.
- (landmark–landmark) is unchanged.
Note. In practice, it is inefficient to update the entire covariance as one single block. is the largest part and remains unchanged during prediction — exploit the sparse structure and update only the relevant sub-blocks.
Bringing it together:
def wrap_angle(a):
"""Wrap to [-pi, pi)."""
return (a + np.pi) % (2 * np.pi) - np.pi
def EKF_SLAM_Prediction(mu_prev, Sigma_prev, u_t, R_x, dt):
"""One step of EKF-SLAM prediction (mean + covariance)."""
n = mu_prev.size
Fx = Fx_embed(n)
# Mean
mu_bar = mu_prev.copy()
mu_bar[:3] = mu_prev[:3] + motion_increment(mu_prev[2], u_t, dt)
mu_bar[2] = wrap_angle(mu_bar[2])
# Covariance
Gt = np.eye(n) + Fx.T @ G_inner(mu_prev[2], u_t, dt) @ Fx
Rt = Fx.T @ R_x @ Fx
Sigma_bar = Gt @ Sigma_prev @ Gt.T + Rt
return mu_bar, Sigma_barCorrection step
We incorporate sensor measurements to refine the current belief about the robot's pose and landmark positions. Assumptions:
- Known data association — each observation is matched to its landmark.
- The measurement at time observes landmark , with .
- Landmarks are initialized when observed for the first time.
1. Range-bearing observation
Each observation at time consists of a range and bearing:
If a landmark has not previously been observed, initialize it from the current robot pose and the measurement:
def init_landmark_from_observation(mu, seen_mask, j, z):
"""Initialize landmark j from current robot pose and observation z = [r, phi]."""
if not seen_mask[j]:
r, phi = z
mu[3 + 2*j] = mu[0] + r * np.cos(phi + mu[2])
mu[3 + 2*j + 1] = mu[1] + r * np.sin(phi + mu[2])
seen_mask[j] = True
return mu, seen_mask2. Expected observation
Compute the expected observation from the current estimate:
def expected_observation(mu, j):
"""Compute predicted range-bearing to landmark j."""
x, y, th = mu[:3]
mx, my = mu[3 + 2*j : 3 + 2*j + 2]
dx, dy = mx - x, my - y
q = dx*dx + dy*dy
r = np.sqrt(max(q, 1e-12))
phi = wrap_angle(np.arctan2(dy, dx) - th)
zhat = np.array([r, phi])
return zhat, np.array([dx, dy]), q3. Jacobian of the observation model
In a low-dimensional space focusing only on (a matrix):
Map it to the full high-dimensional state via the auxiliary :
where selects the robot block and the landmark- block from the full state.
def H_low(mu, j):
zhat, delta, q = expected_observation(mu, j)
dx, dy = delta
r = zhat[0]
q = max(q, 1e-12)
H_small = (1.0 / q) * np.array([
[-r * dx, -r * dy, 0.0, r * dx, r * dy],
[ dy, -dx, -q, -dy, dx],
])
return H_small, zhat
def Fxj_embed(n, j):
Fxj = np.zeros((5, n))
Fxj[:3, :3] = np.eye(3)
Fxj[3, 3 + 2*j] = 1.0
Fxj[4, 3 + 2*j + 1] = 1.0
return Fxj
def H_full(mu, j):
n = mu.size
H_small, zhat = H_low(mu, j)
Fxj = Fxj_embed(n, j)
return H_small @ Fxj, zhatPutting prediction + correction together:
def innovation(z, zhat):
return np.array([z[0] - zhat[0], wrap_angle(z[1] - zhat[1])])
def EKF_SLAM_Correction(mu_bar, Sigma_bar, z_list, c_list, Q, seen_mask):
mu, Sigma = mu_bar.copy(), Sigma_bar.copy()
I = np.eye(mu.size)
for z, j in zip(z_list, c_list):
mu, seen_mask = init_landmark_from_observation(mu, seen_mask, j, z)
H_i, zhat = H_full(mu, j)
S = H_i @ Sigma @ H_i.T + Q # innovation covariance
v = innovation(z, zhat) # innovation
K = Sigma @ H_i.T @ np.linalg.inv(S) # Kalman gain
mu = mu + K @ v
mu[2] = wrap_angle(mu[2])
Sigma = (I - K @ H_i) @ Sigma
return mu, Sigma, seen_maskThe same circular-trajectory example from the prediction section, now with the correction step enabled, shows landmarks getting locked in and the pose covariance shrinking when landmarks are revisited.
The two panels run the same nominal circular trajectory side by side. Left: prediction only — the red position estimate drifts off the dashed ground-truth circle, and the uncertainty disk grows monotonically with every step. Right: with range-bearing observations, the EKF correction pulls the estimate back onto the ground-truth path and the uncertainty disk shrinks each time landmarks are observed. The × marks show the estimated landmark positions converging on the ★ ground-truth landmarks as more observations accumulate.
EKF-SLAM algorithm (summary)
- define F_x (3×n)# low-to-high mapping
- μ̄_t = μ_{t-1} + F_xᵀ · g_velocity(θ, v, w, Δt)# predict the mean
- G_t = I + F_xᵀ · J_velocity(θ, v, w, Δt) · F_x# compute the Jacobian
- Σ̄_t = G_t Σ_{t-1} G_tᵀ + F_xᵀ R_tˣ F_x# predict the covariance
- return μ̄_t, Σ̄_t
- Q_t = diag(σ_r², σ_φ²)# sensor uncertainty
- for each observed feature z_t^i = (r, φ): with j = c_t^i
- if landmark j is new: μ̄_{j,xy} = robot_xy + r · (cos(φ+θ), sin(φ+θ))# initialize if first seen
- δ = μ̄_j − μ̄_t,xy# distance
- q = δᵀδ# squared range
- ẑ = (√q, atan2(δ_y, δ_x) − μ̄_t,θ)# predicted observation
- define F_{x,j} (5×n)# select robot + landmark j
- H_t^i = (1/q) · M(δ) · F_{x,j}# observation Jacobian
- K_t^i = Σ̄_t H_t^iᵀ (H_t^i Σ̄_t H_t^iᵀ + Q_t)⁻¹# Kalman gain
- μ̄_t = μ̄_t + K_t^i (z_t^i − ẑ_t^i)# update mean
- Σ̄_t = (I − K_t^i H_t^i) Σ̄_t# update covariance
- μ_t = μ̄_t, Σ_t = Σ̄_t; return μ_t, Σ_t
Implementation notes
When implementing the full EKF-SLAM algorithm:
- Batch updates. Always integrate all measurements from a single time step into one complete update cycle.
- Angle normalization. Ensure angular components are wrapped to remain within .
- Jacobian efficiency. Avoid explicitly forming the matrices unless necessary — use indexing operations for efficiency.
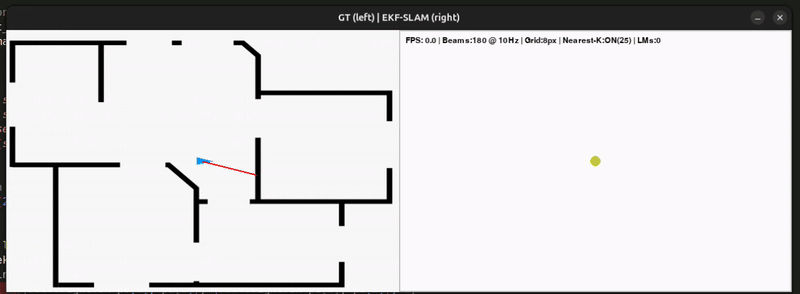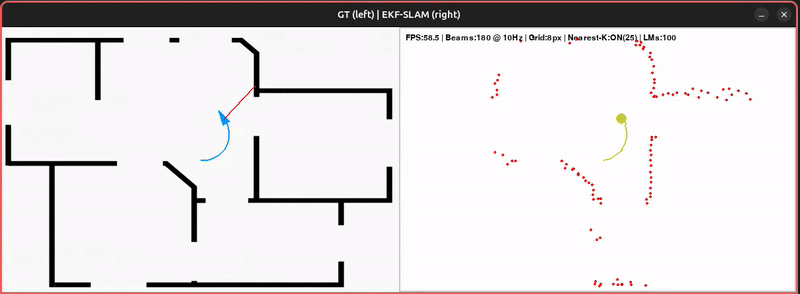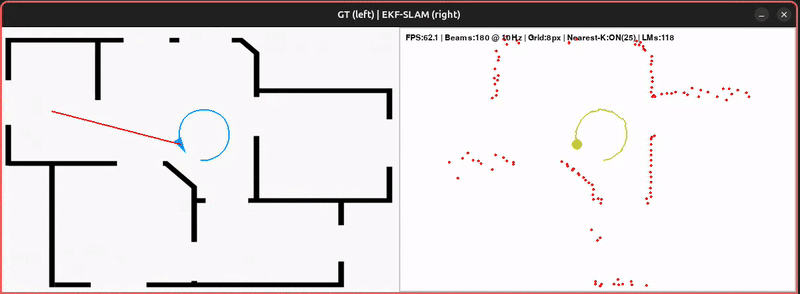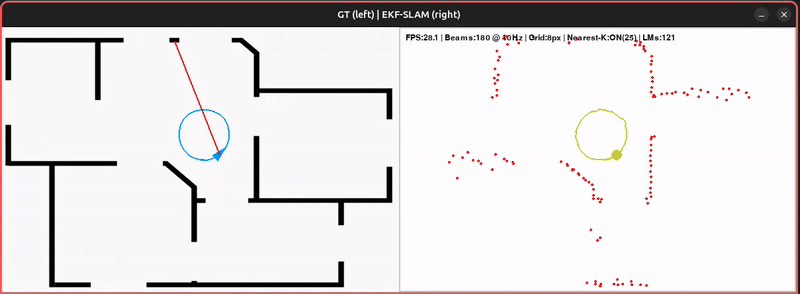
The original notebook extends the Pygame motion-model demo with the EKF correction step. Some practical details:
- Landmark density. Since every LiDAR point is treated as a potential landmark, the state vector grows quickly. The demo discretizes the 2D LiDAR plane into pixel blocks, keeping only one landmark per block.
- Selective updates. Only the nearest subset of landmarks is updated at each step — keeping things efficient while still correcting the map consistently as landmarks are revisited.
- Consistency. The reconstructed map becomes noticeably more stable than the pure motion-model demo. Depending on the neighbour count, you can directly see how nearby landmarks are corrected and reinforced over multiple observations.
What's next?
While the EKF improves upon the standard Kalman filter by handling nonlinear models, it still has limitations. A natural alternative is the Unscented Kalman Filter (UKF).
KF vs EKF
- EKF is an extension of the KF designed to handle nonlinearities.
- It performs local linearizations around the current estimate.
- Works well in practice for moderate nonlinearities and uncertainty.
Unscented Kalman Filter (UKF)
Motivation
- KF requires strictly linear models.
- EKF approximates nonlinear functions with a Taylor expansion.
The UKF avoids explicit Jacobians. Instead it uses the Unscented Transform: it computes a set of carefully chosen sigma points, propagates them through the nonlinear motion and measurement models, and reconstructs a Gaussian from the transformed points.
UKF vs EKF
- Produces the same results as EKF for linear models.
- Provides a better approximation for nonlinear models.
- No Jacobians required.
- Computational complexity is similar, though UKF can be slightly slower.
Reading material
EKF-SLAM
- Thrun, Burgard, Fox. Probabilistic Robotics, Chapter 10.
Unscented Transform and UKF
- Thrun, Burgard, Fox. Probabilistic Robotics, §3.4.