Least-Squares SLAM
Pose-graph constraints and global optimization of trajectories.
As the robot moves, it creates nodes in a graph. Constraints / edges between the nodes come from various sources — odometry estimates, scan matching, etc.

- Constraints are inherently uncertain.
- Observing previously seen areas generates constraints between non-successive poses (loop closures).
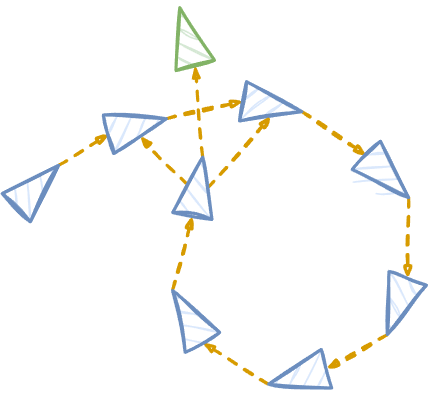
Idea of graph-based SLAM
- Use a graph to represent the problem.
- Every node is a pose of the robot during mapping.
- Every edge between two nodes is a spatial constraint between them.
Goal. Build the graph and find a node configuration that minimizes the error introduced by the constraints.
The graph
- nodes .
- Each is a 2D or 3D transformation (the pose of the robot at time ).
- Create an edge if…
- The robot moves from to → edge corresponds to odometry.
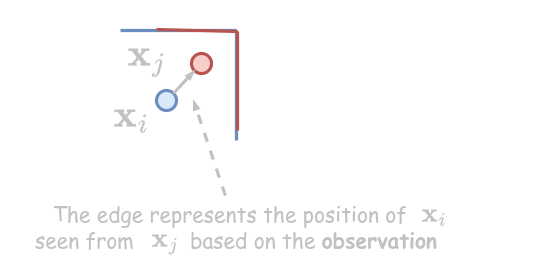
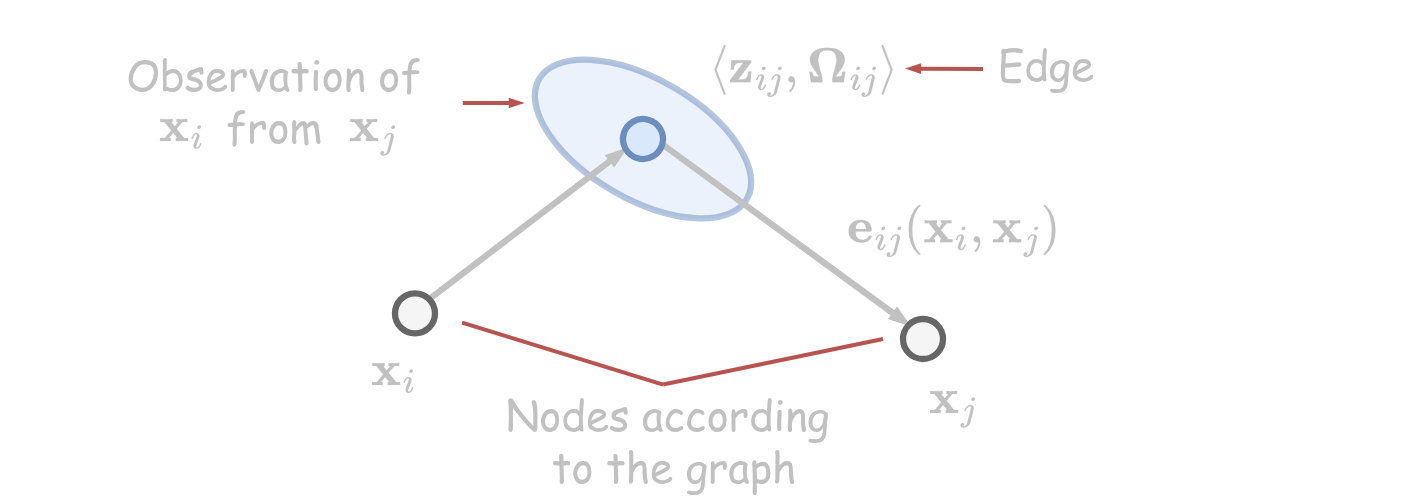
- The robot observes the same part of the environment from and → edge represents the position of seen from based on the observation. We construct a virtual measurement about how node sees node .
Transformations
Transformations are expressed using homogeneous coordinates.
- Odometry-based edge:
- Observation-based edge:
Pose graph
Goal:
Why this form?
Because the error term is strongly related to the expression of a Gaussian distribution . Minimizing is equivalent to maximizing the likelihood of a Gaussian with mean and information .
The sum across edges encodes the assumption that the constraints are independent.
The error function
For a single constraint:
where:
- is the measurement,
- is referenced w.r.t. ,
- converts a transformation matrix to a vector (e.g. ).
The error is zero iff .
Gauss-Newton on the pose graph
The overall procedure mirrors the generic Gauss-Newton recipe:
- Define the error function.
- Linearize it.
- Compute its derivative.
- Set the derivative to zero.
- Solve the linear system.
- Iterate until convergence.
Linearizing the error function
Around an initial guess via Taylor expansion:
Sparsity of the Jacobian
The error depends only on the two parameter blocks and :
The Jacobian is therefore zero everywhere except in the columns of and .

Note. This sparsity is what lets us solve the system efficiently.
Consequences of sparsity
We compute the coefficient vector and matrix for the system :
The sparse structure of leads to a sparse — and that sparsity pattern is exactly the adjacency matrix of the graph.
Switch between the modes to see how the H matrix block structure mirrors the graph: a sequential trajectory gives a banded tridiagonal H; loop closures add off-diagonal fill; landmarks split H into a four-block structure with a dense pose block, a sparse landmark block, and the cross-terms.
Building the linear system
For each constraint:
- Compute the error:
- Compute Jacobian blocks:
- Update the coefficient vector:
- Update the system matrix:
Algorithm
- while not converged:# iterate until convergence
- (H, b) = buildLinearSystem(x)# build sparse normal equations
- Δx = solveSparse(H Δx = −b)# solve sparse system
- x = x + Δx# state update
- return x
A trivial 1D example
Three nodes and one observation per edge:
Error function: .
- Errors: , .
- Jacobians (1×3 row vectors): , .
- Coefficient blocks:
- System matrix:
Try to solve and you'll notice — is singular.
What went wrong?
- The constraints are relative between nodes.
- Any choice of poses works as long as their relative coordinates fit.
- One node needs to be fixed.
Add an extra anchor constraint to :
This anchors to its position. Solving gives — exactly the configuration we'd expect.
Role of the prior
- is not full rank before we fix the global reference frame.
- Fixing the global frame is strongly related to the prior .
- A Gaussian estimate about adds one extra constraint.
To anchor to the origin, add an error function based on a single variable — the transformation of itself:
Fixing a subset of variables
When the value of certain variables during optimization is known, we may want to optimize all others and keep these fixed.
- If a variable isn't optimized, it should "disappear" from the linear system.
- Construct the full system.
- Suppress the rows and columns corresponding to the variables to fix.
Uncertainty
- is the information matrix at the linearization point.
- Inverting gives a (dense) covariance matrix.
- The diagonal blocks of the covariance encode the absolute uncertainties of the variables.
Relative uncertainty
To determine the relative uncertainty between two nodes and :
- Construct .
- Suppress the rows / columns of (this "fixes" ).
- Compute the block of the inverse.
- That block contains the covariance of w.r.t. the fixed .
A live pose-graph optimization: the dashed circle is the ground truth, the solid coloured line is the current estimate, and the faint dashed lines are the loop-closure constraints pulling the path back together. The initial trajectory is built by integrating raw noisy odometry — it drifts off the circle. Each iteration of Gauss-Newton solves a sparse and pulls the estimate closer to a configuration consistent with all the relative-pose constraints.
Does all that run online?
It depends on the size of the graph. At some point the graph grows large enough that optimization becomes slower than the rate at which we add new nodes.
This leads to the hierarchical pose graph — we don't need all of the nodes to optimize our graph.
Hierarchical pose graph
Nodes can represent large chunks of nodes and be optimized as the higher-level node.
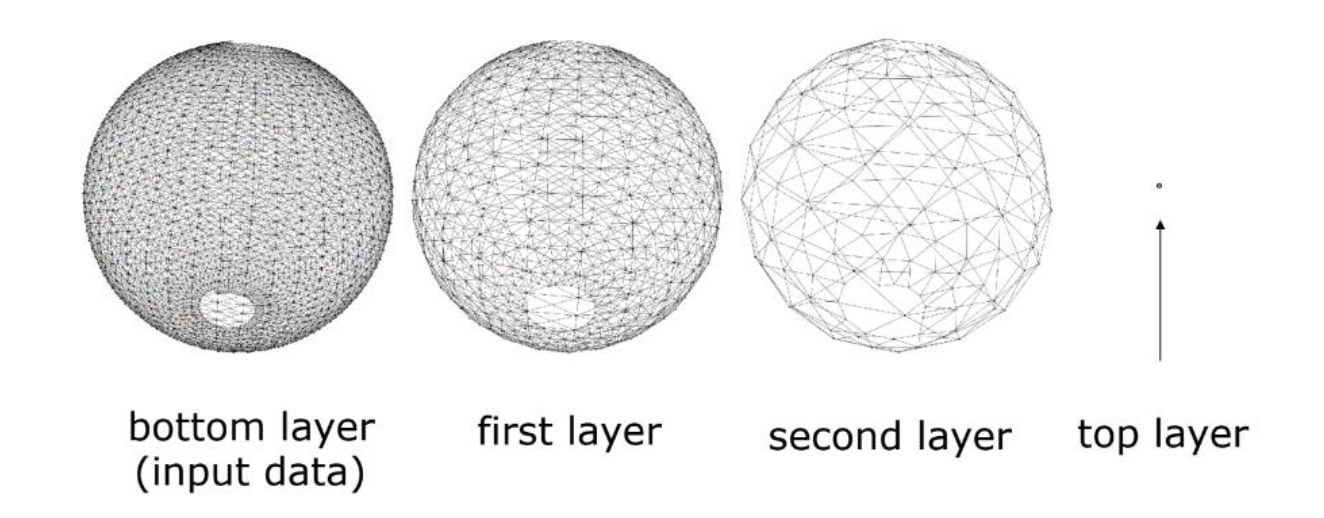
Motivation: "there's no need to optimize the whole graph when an observation is obtained."
- The front-end searches for loop closures.
- That requires comparing observations to all previously obtained ones.
- In practice we limit the search to areas where the robot is likely to be.
- This requires knowing which parts of the graph to search for data associations.
Hierarchical approach
Insight. To find loop closures, we don't need the perfect global map.
Idea. Correct only the core structure of the scene, not the overall graph. The hierarchical pose graph is a sparse approximation of the original problem.
It exploits the fact that in SLAM:
- The robot moves through the scene — it's not "teleported" to locations.
- Sensors have a limited range.
Key idea of the hierarchy
- Input is the dense graph.
- Group the nodes by local connectivity.
- For each group, select one node as a "representative".
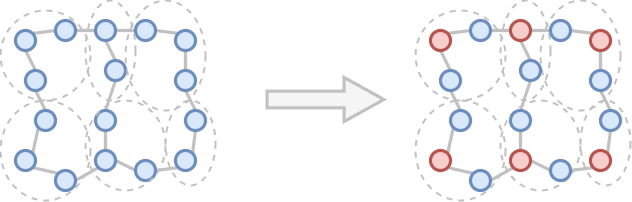
- The representatives are the nodes in a new sparsified upper-level graph.
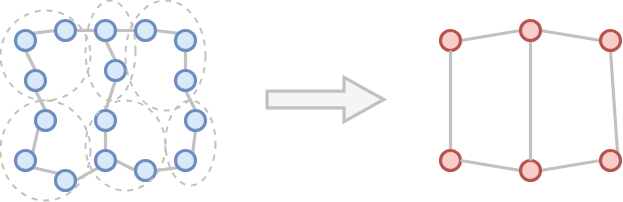
- Edges of the sparse graph are determined by the connectivity of the groups.
- The parameters of the sparse edges are estimated via local optimization.
- Process is recursive.
Only the upper level of the hierarchy is fully optimized. Changes are propagated to the lower levels only near the current robot position — the only part relevant for finding constraints.
Note. Keeping only a portion of nodes/edges makes this an approximation — but a very accurate one in practice.
Construction details
When to start a new group? A simple distance-based decision. The first node of a new group is the representative.
When to propagate information downwards? Only when there are inconsistencies.
Determining edge parameters. Given two connected groups, how do we compute a virtual observation and information matrix for the new edge?
- Optimize the two sub-groups jointly but independently from the rest.
- The observation is the relative transformation between the two representatives.
- The information matrix comes from the diagonal block of :
Effectively we fix , compute relative to it, invert , cut out the block, and invert it back.
Propagating information downwards
All representatives are nodes from the lower level. Information is propagated downwards by transforming the group at the lower level using a rigid-body transformation. Only if the lower level becomes inconsistent do we optimize it.
For the best possible map
- Run the optimization on the lowest level at the end.
- For offline processing with all constraints, the hierarchy helps convergence faster in the presence of large errors.
- In that case, one pass up the tree (to construct the edges) followed by one pass down is sufficient.
Consistency check
How well does the top level represent the original input? Compute the probability mass of the marginal distribution in the highest level vs the true estimated (original problem, lowest level).
Conclusions
- The back-end of the SLAM problem can be effectively solved with Gauss-Newton.
- The matrix is typically sparse.
- This sparsity allows for efficient solution of the linear system.
- One of the state-of-the-art solutions for computing maps.
- Hierarchical pose graphs enable approximate online solutions.
Reading material
Least-squares SLAM
- Grisetti et al. A Tutorial on Graph-based SLAM, 2010.
Hierarchical approach
- Grisetti et al. Hierarchical Optimization on Manifolds for Online 2D and 3D Mapping, 2010.